ExitLag: получите больше FPS при игре в игры на Windows
Если мы обычно играем через Интернет, наверняка не раз скорость и стабильность интернет-соединения вызывали у нас несколько головных болей. Несмотря на то что Windows 10 имеет собственный игровой режим и специализированные игровые роутеры для игры, всегда можно улучшить соединение и оптимизировать Windows, чтобы наше оборудование работало на полную мощность и уменьшало количество дополнительных кадров в секунду, что может привести нас к победе. И это то, что позволяет нам делать ExitLag.
ExitLag — это программа, созданная специально для игроков, которая позволяет нам оптимизировать Windows и максимально настроить соединения с ПК, чтобы уменьшить пинг, увеличить игровой FPS и положить конец всяким зависаниям и сбоям.

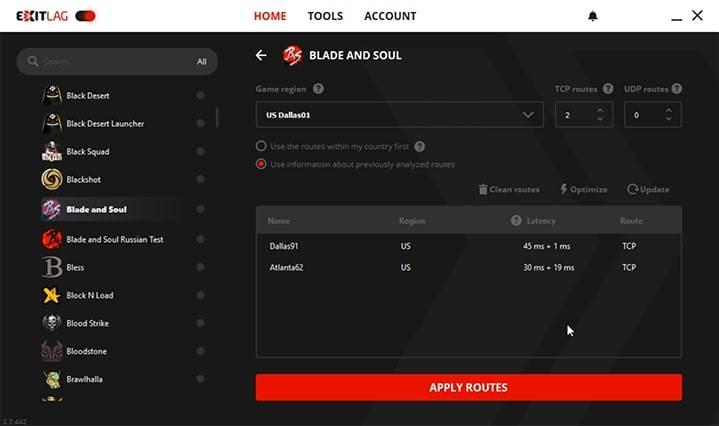
Помимо оптимизации Windows, эта программа позволяет нам улучшить маршруты TCP и UDP, чтобы мы могли легко решить любые проблемы, которые могут повлиять на нашу онлайн-игру. Мы можем использовать ваши собственные VPN и мы даже можем улучшить стабильность и уменьшить потерю пакетов, позволив этому программному обеспечению справиться с этим.
Особенности ExitLag
Основная цель этой программы — оптимизировать как нашу Windows, так и соединения игр. Для этого одна из техник, которые использует эта программа, — многолучевые соединения . Это приводит к одновременной отправке пакетов подключения по разным маршрутам, чтобы гарантировать, что все прибудут в пункт назначения. Программа ищем лучшие маршруты в реальном времени в Для того, чтобы всегда предлагать лучший маршрут для соединений.
Эта программа имеет серверы распространены по всему миру чтобы мы могли подключиться к вашим серверам как можно напрямую и быстро. Кроме того, если у нас есть два Интернет связи в нашем доме он позволяет нам использовать и то, и другое одновременно с его системой балансировки, чтобы гарантировать, что у нас никогда, в любое время, не пропадет связь.
В дополнение к оптимизации соединения, благодаря его Повышение FPS Мы можем оптимизировать Windows, чтобы дать более высокий приоритет играм, которые мы запускаем, и увеличить количество кадров в секунду, а также повысить их стабильность и уменьшить задержку ввода.
Наконец, укажите, что эта платформа совместим с более чем 250 играми , игры, которые мы можем изучить на его главном веб-сайте и где мы найдем самые популярные, такие как Fortnite, DOTA 2, LOL, CS: GO, WOW и многие другие.
Это может не улучшить вашу связь
Хотя в большинстве случаев это поможет нам улучшить наше соединение, эта программа не творит волшебства. Может случиться так, что маршруты нашего интернет-провайдера уже оптимизированы и поэтому использование ExitLag маршрутов не поможет.
Несмотря на то, что это сложно, может случиться так, что маршруты нашего интернет-провайдера лучше, чем маршруты, предлагаемые программой, и, следовательно, могут даже увеличить задержку соединения. В таком случае эта программа не для нас.
Скачать
Эта программа доступна только для Windows (с 7 до 10), и мы можем бесплатно скачать его с Следующая ссылка . Конечно, чтобы использовать его, нам нужно будет зарегистрироваться на вашей платформе.
Требования, которые требует эта программа, ничего не подразумевают, достаточно иметь 100 МБ свободного места. Оперативная память, 30 МБ места на жестком диске и подключение к Интернету со скоростью более 10 Мбит / с, чтобы иметь возможность использовать его.
Оплата подписки
Эта программа предлагает нам бесплатные и необязательный 3-дневный суд , для чего не стоит даже вводить карту. Однако по прошествии этих 3 дней нам придется оформить заказ. И это не совсем дешевая программа.
Оплата лицензии производится по подписке, которая может составлять ежемесячно, 3 месяца или 6 месяцев. Нет модальностей с разными характеристиками, мы должны просто выбрать время, в которое мы хотим использовать услугу, не более того.
Один месяц обслуживания стоит нам $ 6.50 . Если мы подписываемся на 3 месяца сразу, стоимость составляет 6.17 долларов в месяц, а если мы подписываемся на полгода, цена услуги снижается до 5.83 долларов в месяц.
Источник
ДЕВБЛОГ // Оптимизация серверов VALORANT
С самого начала разработки у нас стояли жёсткие требования производительности сервера. В этой статье мы расскажем о том, зачем они нужны, как мы решили наши амбициозные задачи и о технических подробностях наших поисков. Сначала кадр обрабатывался на сервере за 50 мс, а в итоге мы достигли значения менее 2 мс на кадр. Все это благодаря оптимизации кода, работы оборудования и настроек ОС.
Все онлайн-шутеры (удивительно, но даже VALORANT) страдают от преимущества нападающего. Если вкратце, то ключевая задача в VALORANT – занимать и удерживать стратегические позиции. Последнее бывает невозможно сделать, если другой игрок выбегает из-за угла и благодаря задержке передачи данных убивает обороняющегося до того, как тот среагирует. Эта задержка зависит как от сетевого подключения, так и от тикрейта сервера. Чтобы дать обороняющимся время на реакцию, мы решили, что VALORANT нужны серверы с тикрейтом 128. Но об этом мы уже рассказывали в статье про сетевой код.
Главное ограничение для серверов с тикрейтом 128 – ресурсы ЦП. Полный кадр должен обрабатываться за 7.8125 мс, но в таком случае одна игра будет задействовать целое ядро процессора!
На этой схеме показано, сколько игр могут обрабатываться на одном ядре:
Использование целого ядра на одну игру привело бы к большой стоимости обслуживания наших серверов. Но мы хотели, чтобы игра на серверах с тикрейтом 128 была бесплатной для всех игроков, а не премиум-сервисом, доступным за доплату. Вбив цифры в калькулятор, мы определили, что на одном ядре должно обрабатываться более 3 игр. В основном мы используем процессоры с 36 ядрами, то есть каждый физический сервер должен обрабатывать 108 игр, или данные 1080 игроков. 3 игры на ядро – это тоже недёшево, но руководство Riot поддержало наши стремления.
Если разделить 7.8125 мс на 3 игры на ядро, мы получим 2.6 мс. Но еще нужно выделить 10% под работу ОС, планировщик задач и другие процессы на сервере. Получается, что у нас всего 2.34 мс на кадр. Когда мы начинали работу, кадр в VALORANT обрабатывался за 50 мс. Путь оптимизации был долгим и тернистым: для решения этой задачи пришлось бы задействовать всю команду разработки.
«Сделать сервер в 20 раз быстрее» — достаточно абстрактная задача, поэтому мы воспользовались лучшей техникой работы над ПО: разбили большую задачу на маленькие и решаемые по отдельности. Нужно было понять, на что тратятся эти 50 мс, чтобы уменьшить временные затраты. Мы с руководителями технических отделов VALORANT определили большие категории данных, которые требуют много ресурсов ЦП:
- репликация
- «туман войны»
- сеть
- анимации
- геймплей
- движение
- предметы
- персонажи
- физика
- прочее
На основе этого списка мы создали систему, с помощью которой программисты могли легко помечать код игры и делить его на эти категории. Каждая исполняемая строка кода была отнесена к одной из этих областей и включена в макросистему. Также мы добавили разделение на более мелкие подсистемы для точного анализа больших систем. Макросистема получила название ValSubsystemTelemetry.
Теперь при запуске игры мы можем следить за тем, сколько времени уходит на разные категории.
И так, теперь у нас есть библиотека и мы генерируем кучу данных. Что делать?
Работа в крупной студии, типа Riot, позволяет использовать технологии, разработанные другими отделами. В данном случае, основная команда разработала технологию Analytics Platform, используемую для отправки данных в хранилище и визуализации.
Так мы визуализировали данные о производительности VALORANT:
Без таких данных непроизводительные код или изменения контента часто остаются незамеченными. Могло пройти несколько недель, прежде чем эти проблемы накопились и игроки или разработчики заметили бы падение производительности.
Анализ большого количества прошлых обновлений – это очень затратно, но мониторинг данных производительности существенно упрощает задачу. На втором изображении выше можно увидеть проблему между изменениями 445887 и 446832, которая привела к замедлению репликации (оранжевая линия). Такая визуализация сужает массив изменений, и мы можем быстро назначить разработчика для решения проблемы.
После визуализации данных мы смогли установить задачи для каждой подсистемы и разобраться со всеми нестыковками. Мы снова встретились с руководителями технических отделов VALORANT и обсудили, как можно оптимизировать эти системы. Теперь у каждой команды и специалиста была задача, и мы могли вместе работать над улучшением производительности.
Здесь можно увидеть некоторые предварительные данные о категориях, которые упоминались выше:
Для демонстрации оптимизационной работы будет достаточно примеров двух категорий. Сначала мы расскажем о репликации, потому что ей требовались наибольшие изменения (в 10 раз быстрее), а затем поговорим об анимации, потому что её изменения дают хорошее представление о решениях в других категориях.
Репликация объектов или просто репликация – это система в Unreal Engine 4 (UE4), которая позволяет синхронизировать состояние сервера и клиента. Она отлично подходит для быстрого прототипирования новых персонажей, умений и настроек, для которых нужно сетевое взаимодействие с клиентами. Разработчик может просто пометить переменную как «реплицированную», и она будет автоматически синхронизирована между сервером и клиентами.
К сожалению, она довольно медленная. Она сканирует все реплицированные переменные для каждого кадра, потом сравнивает их с 10 последними известными состояниями клиента, выявляет все расхождения и отправляет клиенту изменения. Это по сути рандомные прыжки по памяти и на них требуется много кэша. Переменные проверяются независимо от изменений. Подобные «опрашивающие» системы я считаю антагонистами производительности.
Проблема была решена с помощью другого сетевого инструмента UE4 – удаленного вызова процедур (RPC). Он позволяет серверу удаленно вызывать функции, исполняющиеся на одном или нескольких клиентах. Использование RPC при изменении состояний во время игры ограничивает затраты производительности кадром, в котором происходит изменение. Такая модель «пушей» намного эффективнее. Недостаток в том, что дизайнерам и инженерам приходится более внимательно рассчитывать, где стоит использовать RPC и вызывать возможное переподключение. Несмотря на это, в большинстве случаев замена реплицированных переменных на RPC увеличила производительность в 100–10 000 раз!
Например: здоровье персонажа. Можно пометить переменную здоровья как реплицированную. Сервер проверял бы изменение значения для каждого кадра и корректировал бы значение для клиентов. А с помощью RPC можно отправить с сервера событие «Попадание» и значение урона. Клиенты синхронизируются, применив это значение к здоровью игроков.
Анимация требовала больших ресурсов сервера. Чтобы корректно определить попадание, нужно воспроизводить на сервере те же анимации, которые воспроизводятся на стороне клиентов. Попадания в VALORANT определяются с помощью сохранения позиции и состояния анимации игрока в буфере. Когда сервер получает от клиента пакет данных о выстреле, он восстанавливает позицию и анимацию игрока из буфера, чтобы рассчитать попадание. Изначально мы обрабатывали анимацию и заполняли буфер для каждого кадра. Но после тщательного тестирования мы выяснили, что можно делать это лишь для каждого четвертого кадра, а при восстановлении использовать линейную интерполяцию (lerp) сохраненных анимаций. Это позволило уменьшить затраты производительности на 75%.
Кроме того, мы выяснили, что производительность сервера – это самая важная часть производительности в целом. Представьте, что сервер VALORANT обрабатывает около 150 игр. В любой момент времени около 50 игр будут в фазе покупок. Когда игроки покупают снаряжение, они находятся в безопасной зоне и не могут получить урон сервера. А значит, можно просто отключить анимации на сервере! Что мы и сделали. Со стороны сервера во время фазы покупок игроки неподвижны. Затраты на анимацию в каждом раунде уменьшились на 33%!
Теперь вы знаете, как мы оптимизируем код. Но производительность не ограничивается кодом. Важна ещё и платформа, на которой все работает. Давайте обсудим то, что ещё вызывало серьёзные проблем производительности — операционная система и железо.
Чтобы выяснить, как будет вести себя игра в реальном мире, нужно было провести нагрузочное тестирование. Мы хотели выяснить, как физический сервер справится с обработкой более 100 виртуальных серверов на одном ЦП. Это тестирование было критически важно для успешного запуска VALORANT. Мы смогли точно определить, сколько ядер нужно на одного игрока, и устранить ряд ошибок, которые мы не увидели бы без большой нагрузки на сервер. Все оказалось сложнее, чем 7.8 мс в 3 играх на ядро.
Давайте сначала посмотрим на этот график. По оси X – число виртуальных серверов, по оси Y – время обработки кадра.
При единственном сервере мы имеем отличное значение 1,5 мс. Но для 168 серверов время увеличивается до 5,7 мс.
Чтобы понять, почему это происходит и как мы с этим справились, сначала нужно взглянуть на архитектуру современных ЦП.
На изображении вверху можно заметить, что каждое ядро имеет собственную кэш-память L1 и L2, но большой кэш L3 разделен между ядрами. Если на стороне хоста работает единственный сервер, он хранит весь кэш L3, что приводит к меньшему числу ошибок, потому что ядру ЦП требуется меньше времени на ожидание запроса памяти. Поэтому в сценариях с низкой нагрузкой наши серверы работали быстро, но с распределением кэша на большее число виртуальных серверов они замедлялись. Мы с командой специалистов по облачным вычислениям Intel провели некоторые измерения, убедились, что температура и другие значения остаются приемлемыми, и сосредоточились на производительности кэша.
К счастью, у Intel были полезные инструменты измерения и анализа. Мы все еще пользовались более старыми процессорами Intel Xeon E5 с инклюзивной организацией кэш-памяти. Это означает, что все данные в кэше L2 должны присутствовать и в кэше L3. Если данные удаляются из кэша L3, они также удалятся из кэша L2! Получается, что хотя каждый раздел кэша L2 находится на отдельном ядре, на некоторых ядрах кэш L2 мог очиститься, если данные удалялись из кэша L3.
Неприятно, не так ли? В процессорах Intel Xeon Scalable используется неинклюзивная кэш-память, и на них такой проблемы нет. Мы перешли на эти процессоры и значительно увеличили производительность серверных приложений. Последствия разногласий на третьем уровне кэш-памяти еще остались, но производительность увеличилась где-то на 30% при той же частоте ядер.
Мы хотели, чтобы серверы работали еще быстрее. Давайте разберем еще одну особенность архитектуры современных процессоров: неравномерную память (NUMA). Серверы часто двухсокетные. Каждый сокет обеспечивает доступ к участку оперативной памяти системы и передает данные друг другу через общее соединение. Это увеличивает пропускную способность памяти (соединений вдвое больше), но взаимное соединение может стать «бутылочным горлышком». На последней схеме показана упрощенная двухпроцессорная архитектура NUMA. Вот бы операционная система могла выделять память и ресурсы ЦП на уменьшение потока данных через взаимное соединение.
Оказывается, многие современные ОС совместимы с NUMA и могут выполнять такие операции. Например, на Linux это можно сделать с помощью утилиты numactl. Мы переключаем процессы на сервере между нодами таким образом:
Эта небольшая оптимизация использования архитектуры увеличила производительность примерно на 5%. Доступ к памяти NUMA-узлов увеличился с 50% до 97-99%. В дополнение к этим 5%, виртуальные серверы стали работать намного стабильнее!
Во время мониторинга сервера игры мы заметили интересную особенность: ядра бывали загружены на 90–96%, но никогда не нагружались на 100%, даже при загрузке количества игр, вдвое превышающего предполагаемый максимум для сервера. Мы предположили, что причина может быть в планировщик. С помощью инструмента мониторинга процессов Adaptive Optimization от Intel и Linux-утилиты perf мы стали разбираться в проблеме. Linux также дает возможность увидеть исходный код планировщика.
Мы выяснили, что современные системы Linux используют планировщик Completely Fair Scheduler (CFS). Это очень хорошая и оптимизированная программа. Например, она назначает процессы на одно ядро и не дает им мигрировать и запускаться на других ядрах. Это делается для того, чтобы процессы использовали ещё «горячие» линии кэша. Также простаивающие ядра не задействуются без необходимости. Процесс ожидает поступления на занятое ядро в течение некоторого времени, прежде чем CFS разрешит ему обработаться на другом свободном ядре. Значение этого времени ожидания по умолчанию на нашем дистрибутиве Linux было равно 0.5 мс.
Для VALORANT 0.5 мс это слишком долго, учитывая нашу цель в 2.34 мс. За это время можно обработать почти 1/4 кадра! Ни на одном из участков памяти сервера к этому времени не останется горячего кэша. Когда один сервер игры простаивает между кадрами, остальные серверы используют кэш по-максимуму. Если уменьшить время ожидания миграции процессов до 0, планировщик немедленно задействует игровой сервер на любом доступном ядре системы. Так мы рациональнее используем ресурсы ЦП для работы системы и увеличиваем производительность на 4%. Кроме того, мы заметили, что теперь время простоя отдельных ядер уменьшилось почти до нуля!
Также мы контролируем состояние сна (C-режим, или C-State), в которое может входить процессор. Многоядерный процессор позволяет ядрам пребывать в различных режимах энергопотребления. При низкой загрузке ядра часто входят в C-режим для снижения потребления энергии. При увеличении загрузки им требуется время, чтобы вернуться к более активному состоянию. В системах с цикличной нагрузкой, таких, как игровые серверы, ЦП начинает часто переключать C-режимы. У каждого переключения есть задержка, и это снижает производительность. Мы ограничили сон до менее глубоких состояний (C0, C1 и C1E) и смогли стабильно обрабатывать еще 1–3% игр. В итоге была оптимизирована производительность 60–90% загруженных серверов, у которых раньше при уменьшении нагрузки ядра часто простаивали.
Гиперпоточность — это технология архитектуры ЦП, при которой одно физическое ядро может выполнять два потока одновременно. При гиперпоточности части ядра могут вместе использоваться для некоторых процессов (как кэш), а иногда дублироваться (как отдельные вычислительные ядра).
Все зависит от конкретного процессора. В начале разработки у нас было 25 мс на кадр, а отключение гиперпоточности снизило время обработки кадра до 20 мс. Производительность увеличилась на 25%! Но наши друзья из Intel отнеслись к этому скептически. С учетом нашей загрузки мы могли задействовать больше ресурсов оборудования, если бы использовали виртуальные ядра гиперпоточности. Мы прислушались, снова включили гиперпоточность и опять увеличили производительность на 25%.
Как это произошло? Процессоры Intel Xeon Scalable позволили улучшить производительность кэш-памяти и гиперпоточности. Также мы настроили планировщик, чтобы рациональнее использовать доступные ядра, запретили C-режимы глубже C1E для меньшей задержки производительности ядер и приняли другие меры по оптимизации. Мы уменьшили время обработки кадра сервером и достигли гораздо лучших результатов, чем наша изначальная цель в 7,8125 мс.
Нужно учитывать, что производительность каждого приложения различна. Даже то же самое приложение может требовать других ресурсов годы спустя. Поэтому нужно создать воспроизводимые тесты и измерять.
Если просто составить список «способов улучшить производительность», о которых вы узнали, скажем, из блога разработчиков игр, и использовать эти способы без учета особенностей своего приложения, вы можете не только не увеличить производительность, но и уменьшить ее.
В играх часто отмечается прохождение времени. Это делается с помощью системных запросов к ОС через источник времени. ОС, работающая на низкоуровневом окружении (как AWS), может использовать виртуальные источники времени, но они менее производительны. Мы сначала пользовались источниками времени Xen от одноименного гипервизора на нодах AWS. Затем мы переключились на tsc, инструмент из инструкции к ЦП rdtsc, и смогли увеличить производительность игровых серверов на 1–3%.
Приближалась дата релиза, и мы заметили, что один из нагрузочных тестовых серверов менее производителен, чем другие. Железо было идентичным, единственная разница была в том, что он обрабатывал полностью развёрнутое приложение. Нагрузочные тесты показывали в 2–3 раза больше задержек и замедлений кадров, чем на оборудовании, которое я настроил вручную. Мы все проверили – и гипервизор AWS, и различия в конфигурации, и даже исправность оборудования. Все было в порядке.
Мы догадались снова проверить диспетчер Linux с помощью perf shed, чтобы посмотреть, нет ли разницы в процессах. И обнаружили, что каждые 5 секунд запускались 72 процесса: от scheduler_1 и до scheduler_72. По одному на каждое виртуальное ядро. Они сразу же занимали все ядра, предназначенные для серверов игры. Это приводило к постоянным задержкам на загруженных серверах. Оказалось, что наш инструмент для развертывания Mesos использовал для метрики Telegraf, а он делал DNS-запросы каждые 5 секунд. Вызывалось приложение dcos_net, написанное на Erlang.
В Erlang можно настроить количество потоков, которое может обрабатывать диспетчер. Значение по умолчанию – один поток на ядро, отсюда те самые 72 процесса. Мы установили более оптимальное значение 4, и проблема сразу же решилась. Мораль такова: очень важно измерять производительность в той конфигурации, которая совпадает с рабочей средой!
Не увидеть за деревьями леса – очень легко. Даже в этом кратком рассказе о нашем увеличении производительности очень много технических подробностей. В мелких деталях, инструкциях и хитрых способах легко запутаться.
Нужно постоянно оценивать и пересматривать задачи производительности. В эти процессы должна быть вовлечена целая команда, которая всегда поможет в нужный момент.
Оптимизация кода – важная часть производительности, но нужно разделить производительность приложения на отдельные категории и не забывать об окружении (оборудовании и операционной системе). Тогда ваше приложение будет работать максимально эффективно.
Измерения прежде всего! Именно благодаря измерениям мы смогли определять требуемые ресурсы оборудования с погрешностью не более 1%. Поэтому запуск прошел успешно, а вы играете в VALORANT на серверах с тикрейтом 128!
VALORANT — командный тактический шутер от первого лица, выпущенный Riot Games. Сейчас в игре начался Акт 3, с которым в игру была добавлена новая карта Icebox, а 28 числа выйдет новый агент Skye!
А если вам интересно узнать больше о разработке VALORANT, то можете ознакомиться с нашими статьями:
Источник